






Une équipe de neuro-ingénieurs américains vient de mettre au point une intelligence artificielle (IA) capable de convertir le signal électrique du cerveau en paroles. Leurs résultats viennent d'être publiés en accès libre dans la revue Scientific Reports.
Jusqu'à présent, les applications réelles de ce type de système restaient limitées. Des chercheurs avaient par exemple réussi à piloter un drone par la pensée, ou à faire collaborer trois personnes pour jouer au jeu Tetris. À chaque fois, le système repose sur des commandes très simples qui nécessitent une concentration particulière. Pour cette nouvelle expérience, le sujet n'effectue aucun effort conscient.
Une approche basée sur le « deep learning »
La recherche menée porte non pas sur la vocalisation des pensées des sujets, mais sur les mots entendus. Pour cela, les chercheurs se sont intéressés au cortex auditif, la partie du cerveau qui reçoit et analyse les informations extraites des sons. Il s'agit d'un défi de taille, puisque la tâche reste similaire, à savoir transformer les signaux du cerveau en sons. Cette approche a l'avantage de permettre une comparaison entre ces signaux et les mots entendus. Ils utilisent ensuite les technologies du deep learning pour analyser leurs enregistrements et entraîner l'intelligence artificielle à reconnaître les mots.
Concrètement, les chercheurs ont utilisé un système d'électrodes invasif pour mesurer l'activité du cerveau. Ils ont profité d'une intervention neurochirurgicale sur des patients atteints d’épilepsiepour implanter des électrodes afin de procéder à des mesures d'électroencéphalographie intracrânienne. Les chercheurs ont ensuite demandé aux patients d'écouter des histoires, lues par deux hommes et deux femmes. À cause des conditions imposées par l'intervention, les histoires ont été limitées à une durée totale de 30 minutes. Elles ont servi d'entraînement à l'intelligence artificielle, qui a comparé les signaux enregistrés avec les textes.
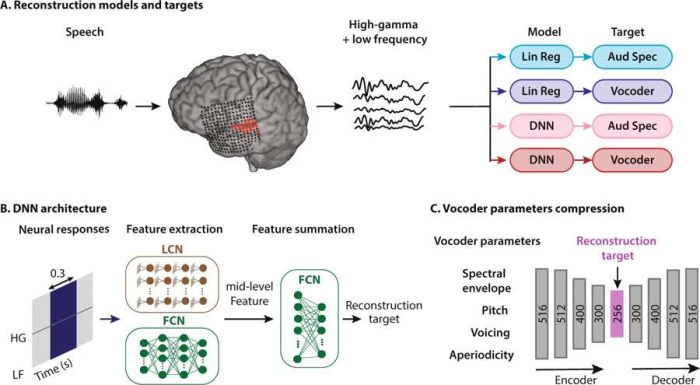
Comment transformer les signaux du cerveau en sons. © Scientific Reports
Des résultats très prometteurs
Les chercheurs ont ensuite utilisé huit phrases, d'une durée totale de 40 secondes, pour tester le modèle de manière objective. Ils ont également procédé à des tests d'intelligibilité subjective. Ils ont utilisé 40 enregistrements de chiffres, soit les chiffres zéro à neuf (qui ne faisaient pas partie des histoires lues précédemment) prononcés par deux hommes et deux femmes différents de ceux qui ont lu les histoires.
L'intelligence artificielle a reconstruit les sons des chiffres à partir des signaux enregistrés, qui ont ensuite été entendus par 11 volontaires. Ceux-ci ont dû indiquer le chiffre, noter la qualité de la reconstruction, puis indiquer le genre du locuteur originel.
Les chercheurs ont obtenu un taux d'identification du chiffre de 75 %, avec un score moyen de 3,4 sur 5 attribué par les volontaires. Ceux-ci ont également pu identifier le genre du locuteur avec un taux de réussite de 80 %.
La prochaine étape des recherches devrait porter sur la reconstruction de mots et de phrases plus complexes. Les chercheurs pourront ensuite tenter de transposer leur technique sur les aires du cerveau responsables de la parole. S'ils parviennent à trouver un système moins invasif, ce système pourrait alors être utilisé pour commander des appareils par la pensée, ou alors redonner la parole à ceux qui ont perdu la capacité de parler.
Source: Futura Sciences
Tags: science






































